
Для создания таких моделей существует множество различных типов алгоритмов, таких, как Scale-invariant feature transform (SIFT), Detectron, RefineDet или You Only Look Once (YOLO). Их часто используют в самых разных отраслях, начиная с автономного вождения и охранных систем, заканчивая автоматизацией на производстве и распознаванием лиц.
Как и с любой моделью машинного обучения, всё начинается с создания обучающего набора данных. Сделать это можно разными способами: можно заказать разметку данных, а можно всё сделать самому.
Конечно, второй вариант займет намного больше времени и сил, но с помощью правильно подобранного ПО можно неплохо упростить задачу. Сейчас я подробно расскажут, как быстро создать обучающий датасет для задач детекции объектов YOLO с помощью Label Studio.
Шаг 1: сбор данных
В зависимости от вашей сферы применения, вы можете столкнуться с проблемой специфичности данных. На данный момент в открытом доступе можно найти множество датасетов с фотографиями улиц с нужными для вашей нейросети объектами. Более того, подобные изображения можно легко спарсить, подобрав релевантные запросы.
С более специфичными данными придется проявить смекалку. Например, в моей компании был кейс, когда мы собирали датасет с мусорными свалками в РФ. Для того, чтобы собраться достаточное количество данных, мы обратились к комьюнити Пикабу и люди делились фотографиями мусорных свалок в своих городах.
Собрать “Мусорный датасет” можно было бы и с помощью краудсорсинга. В Яндекс.Толоке предусмотрен функционал для “сбора в полях”. Хотя создание заданий, ТЗ и инструкций для толокеров требует опыта. Без него есть вероятность получить много нерелевантных данных.
Конечно, можно и просто обратиться в компанию, которая оказывает услуги сбора и разметки данных под ключ. Это сэкономит время, но нужно закладывать бюджет, что для личных разработок или стартапов будет достаточно проблематично.
Помните, что LabelMe предоставляет особые условия для стартапов. Мы сами прошли этот путь и хотим помогать энтузиастам в сфере машинного обучения и искусственного интеллекта.

В качестве примера для статьи мы воспользуемся общедоступным датасетом aerial-home-images, в котором собраны аэрофотографии домов. Будем считать, что данные собраны. Переходим к разметке.
Шаг 2: Разметка данных
Предположим, что наша задача подразумевает детекцию различных классов объектов для кадастрового учета. Например, модель будет определять на снимках дома, бассейны, заборы, навесы, подъездные пути и так далее. Работать будем в Label Studio. Если вы прежде его не устанавливали, в этой статье есть подробная инструкция по установке и первом запуску.

После запуска Label Studio переходим в настройки проекта разметки. Импортируйте свои данные и настройте интерфейс маркировки. Для нашей задаче по детекции нам лучше всего подходит шаблон «Object Detection with Bounding Boxes» или, проще говоря, разметка прямоугольниками.
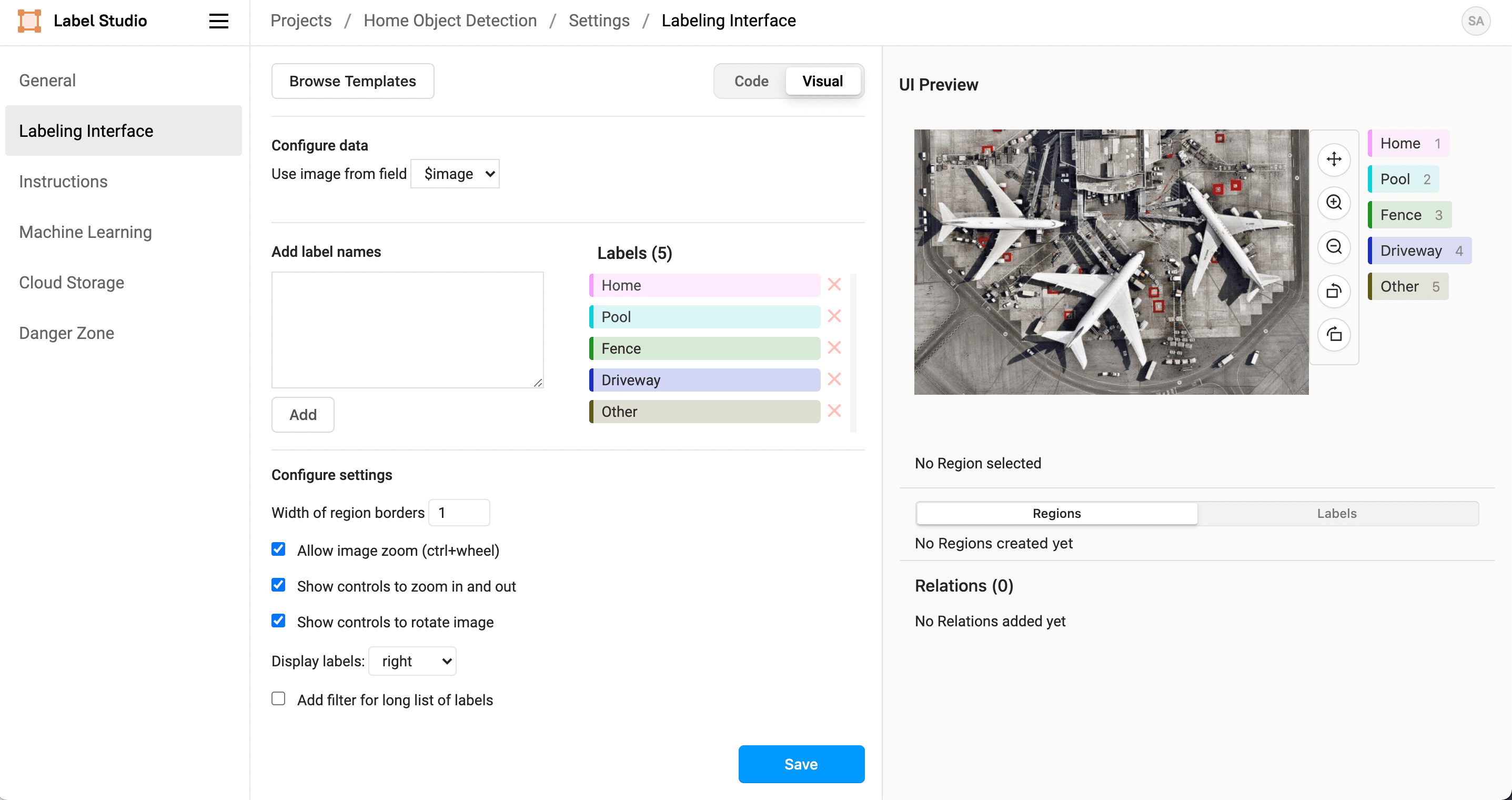
– Home
– Pool
– Fence
– Driveway
– Other
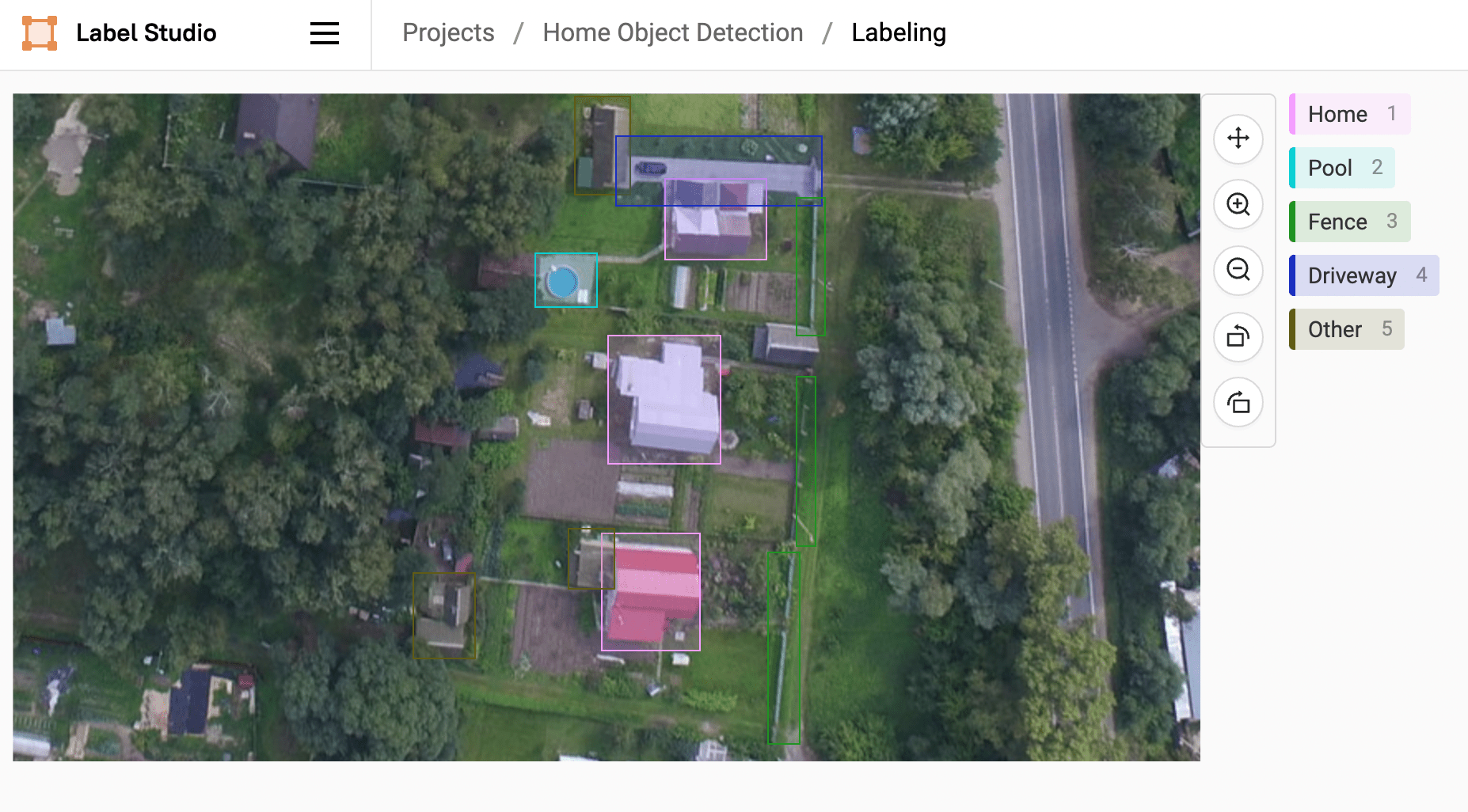
Далее приступаем к разметке. Если вы работаете самостоятельно – запаситесь терпением и включите медитативную музыку. Если у вас есть команда – разделить весь объем данных поровну. Благо Label Studio даёт такой функционал из коробки.

Совет: для создания ограничительной рамки не обязательно зажимать ПКМ и выделять объект. Просто щелкните один раз в том левом углу от объекта и затем еще раз с противоположной стороны.
При разметке данных для модели обнаружения объектов помните о следующих нюансах:
– Следите за тем, чтобы было примерно равное количество примеров по каждому классу. Например, убедитесь, что домов с бассейнами столько же сколько домов без бассейнов, если вы хотите, чтобы модель точнее обнаруживала бассейны.
– Следите за тем, чтобы ограничивающая рамка была не слишком далеко от объектов, но и не пролегала через них. Старайтесь размечать прямо по контуру объекта.
– Отметьте не менее 50 изображений домов, чтобы обучить модель.
– Ограничьте количество объектов, которые вы хотите обнаружить, чтобы повысить точность модели для обнаружения этих объектов. Если вы решите сразу обучить нейронку на детекцию 15 классов, результаты будут далеки от идеальных.
Разметили весь датасет? Тогда импортируем данные.
Шаг 3: Экспорт датасета в формате YOLO и обучение модели
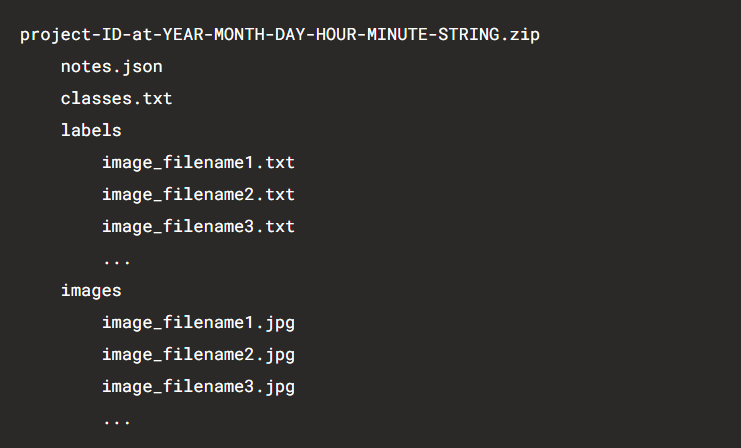
Убедитесь, что все изображения и объекты размечены, а затем кликайте на экспорт и выбирайте YOLO. После этого начнется загрузка zip-архива. Экспортированные данные имеют следующую структуру:
Чтобы обучить вашу модель YOLO с помощью созданного набора данных, вам необходимо указать имена классов и количество классов, а также URL-адреса файлов со списком всех изображений, которые вы будете использовать для обучения. Подробнее об этом можно прочитать в официальной документации для YOLOv3 и YOLOv4.
Экспортированная разметка в формате YOLO из Label Studio включает в себя файл classes.txt. Он уже содержит имена классов, которые использовались при аннотировании изображений, а также каталоги, включающие исходные изображения в каталоге images и файлы .txt с координатами ограничительных рамок для каждого изображения. Выглядит это вот так:

После того, как вы настроите среду модели YOLO для обучения, вы можете тренировать модель с помощью своего датасета. С помощью обученной модели вы можете анализировать новые аэрофотоснимки домов и определять важные объекты, имеющие отношение к вашему варианту использования нейросети.
Заключение
Создание набора данных и обучение пользовательской модели детекции объектов в YOLO – может занимать много времени и быть очень трудоемким. Но в связке с разметкой данных в Label Studio процесс становится намного проще.
Во-первых, у Label Studio удобный и понятный интерфейс. Есть горячие клавиши, позволяют ускорить процесс разметки.
Во-вторых, есть возможность разделить весь набор данных между несколькими разметчиками. Это тоже оптимизирует работу.
В-третьих, экспортный файл уже содержит всю информацию в нужном виде для того, чтобы использовать его YOLO v3 и v4.
Надеюсь, эта туториал был полезен и интересен. Всем хорошей разметки!