
Разработка и внедрение технологий, использующих компьютерное зрение, становится одним из самых востребованных методов использования ИИ в самых разных отраслях. Например, детекция дефектов на производстве, системы беспилотной навигации, биометрические системы безопасности.
Хотя помимо таких важных и серьёзных задач, CV может быть полезна в самых обыденных ситуациях. Определение количества калорий еды по фото, интеллектуальное распознавание показаний счетчиков, функционирование магазинов формата “take and go”. Без труда можно привести еще с десяток примеров и еще сотню — просто придумать.
За любой технологией компьютерного зрения лежит разметка данных в больших объемах. Чтобы научить компьютер отличать объекты, нужно собрать и корректно разметить тысячи примеров. Более того, для каждой сферы применения используются разные виды аннотации данных.
Сегодня мы подробнее расскажем, какая разметка данных используется для разных задач компьютерного зрения.
Bounding Box
Bounding box - это разметка данных с помощью прямоугольников. С ее помощью модель обучается обнаруживать объекты и оценивать их положение в кадре. Эти модели часто используются для подсчета и отслеживания объектов на изображениях или видео.
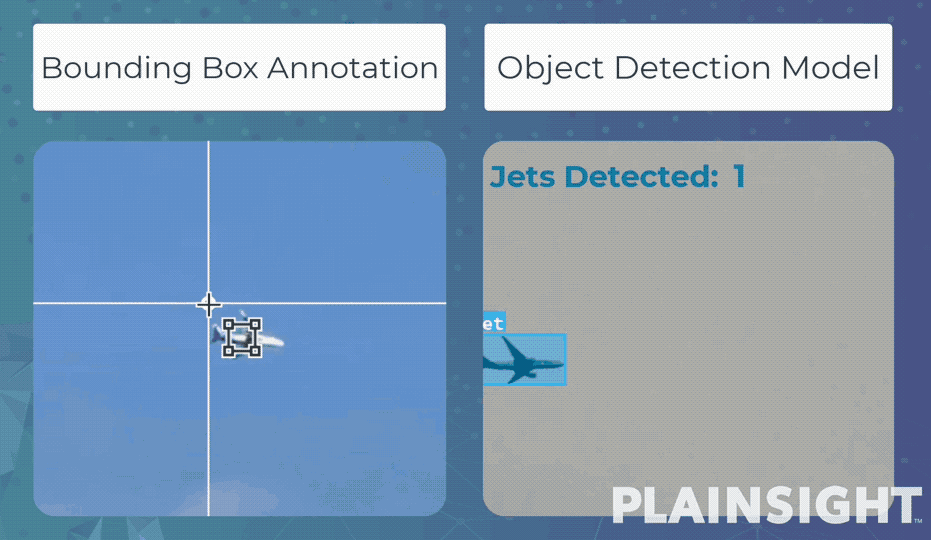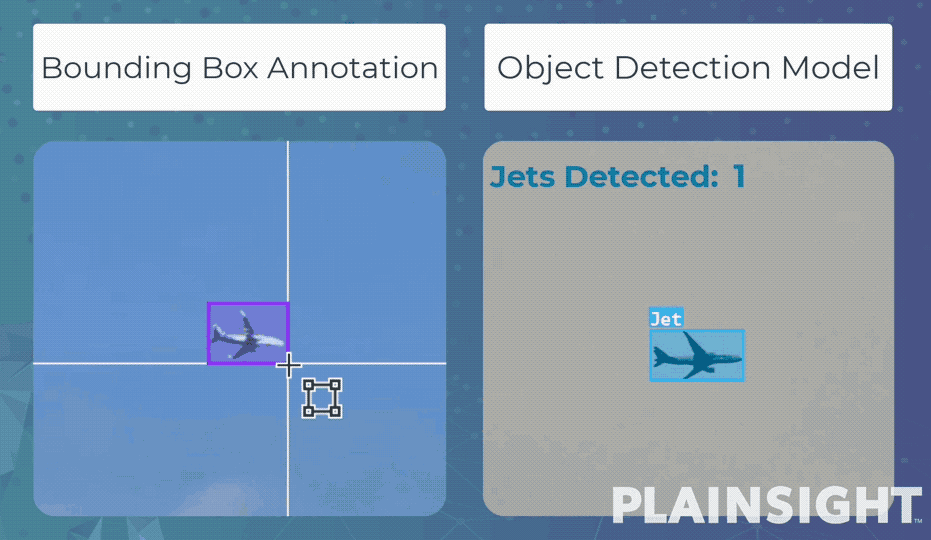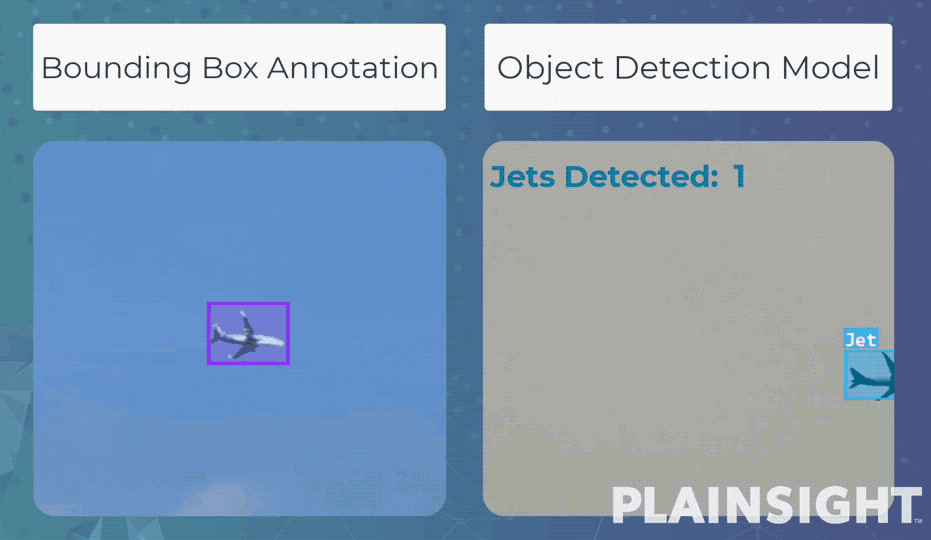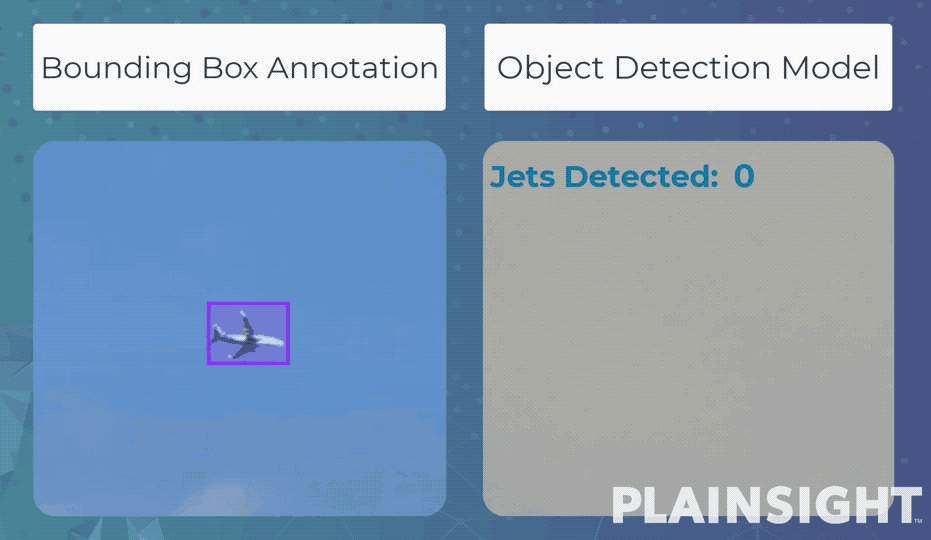
Например, распознавать и подсчитывать людей на видео, полученных с камер наружного наблюдения. Или, при обучении более глубокой модели, обнаруживать различные предметы на интроскопе вокзалов и аэропортов.
В LabelMe мы выделяем три подвида разметки Bounding box:
1. Выделение объектов одного класса — для очень узкоспециализированных задач.
2. Многоклассовая разметка — при наличии двух и более классов объектов.
3. Разметка 3D-кубоидами — когда важно не только обнаружить объект, но и оценить его габариты, положение и траекторию движения.
Семантическая сегментация
Семантическая сегментация — это разделение изображения на отдельные группы пикселей. Каждая группа относится к определенному объекту и выделяется по контуру, создавая цветовую маску. Она используется, когда важно не только определить положение каждого объекта в кадре, но и оценивать точные пиксели каждого объекта.

В отличие от Bounding Box такая разметка позволяет более точно оценивать взаимодействия пикселей каждого объекта. Поэтому важно, чтобы разметчик очень аккуратно и точно размечал необходимые классы объектов по контуру. Далее полученные цветовые маски выгружаются в виде сегментационных масок.
В LabelMe мы выделяем три подвида сегментации:
1. Matting сегментация — когда мелкие детали сливаются с фоном, наш разметчик использует значения от 0 до 1 для подобных областей. Это позволяет очень точно разделить ключевой объект от фона.
2. Многоклассовая сегментация — используется тогда, когда в одной сцене присутствует несколько классов объектов. Например, на одном фото нужно выделить машины, дорогу, деревья и знаки.
3. Парсинг изображения — также же, как и matting разметка покрывает все пиксели изображения. На выходе получается датасет изображений, полностью покрытых масками классов с не пересекающимися границами.
Классификация изображений и видео
Классификация данных - осуществляется двумя способами. Первый — сортировка данных, согласно логике ТЗ. Например, в один архив собираются все автомобили марки BMW, в другой только автомобили Audi.
Второй способ — присвоение классификационных или мультиклассификационных меток, которые применяются ко всему изображению, сигнализирующему, если кадр содержит определенный класс. Например, разметчику нужно выбрать, какое животное изображено на фотографии.

Модели классификации учатся предсказывать, появляется ли определенный объект в изображении или видео, но не оценивают его местоположение или количество экземпляров. Как видно на примере, такую модель можно использовать на пропускных пунктах, чтобы вести учет вошедших/ушедших людей.
В LabelMe мы выделяем три подвида классификации данных:
1. Классификация данных по точным классам — например, присвоить изображению метку “авто”, “мотоцикл” или “велосипед”.
2. По классам и подклассам — когда нужно не только разделить изображения на классы “мотоцикл” и “авто”, но и далее отсортировать по маркам производителей.
3. По инвариантным преобразованиям — если вы ваша модель будет обучена только фотография лежащих кошек, то алгоритм может не определить или определить некорректно классы стоящих или сидящих кошек. Поэтому для увеличения точности важно учитывать изменения ракурсов, освещения, поз и других переменных условий.
Key Point Annotation
Key Point Annotation - разметка ключевыми точками, которая чаще всего используется для оценки поз тела, распознавания жестов рук или мимики лица. В процессе выполнения разметчик должен отметить все ключевые точки согласно логике ТЗ.

Для некоторых задач важно использовать точки разного цвета согласно классам. Например, правая рука размечается красными кнопками, левая - желтыми, правая нога - синими, левая нога - зеленым. Это необходимо для того, чтобы модель более четко оценивала позиции и движения соответствующих конечностей.
Почему качество разметки данных важнее всего?
Сбор и разметка данных занимают до 80% всего времени затраченного на реализацию ML-проекта. Любые ошибки, влияющие на качество датасета, обязательно скажутся на финальной технологии.
Например, если ограничивающие рамки BBox охватывают не весь объект или, наоборот, рамках слишком велика, то точность детекции конечной модели будет низкой. Возможно настолько, что ее не допустят в дальнейший продакшн.
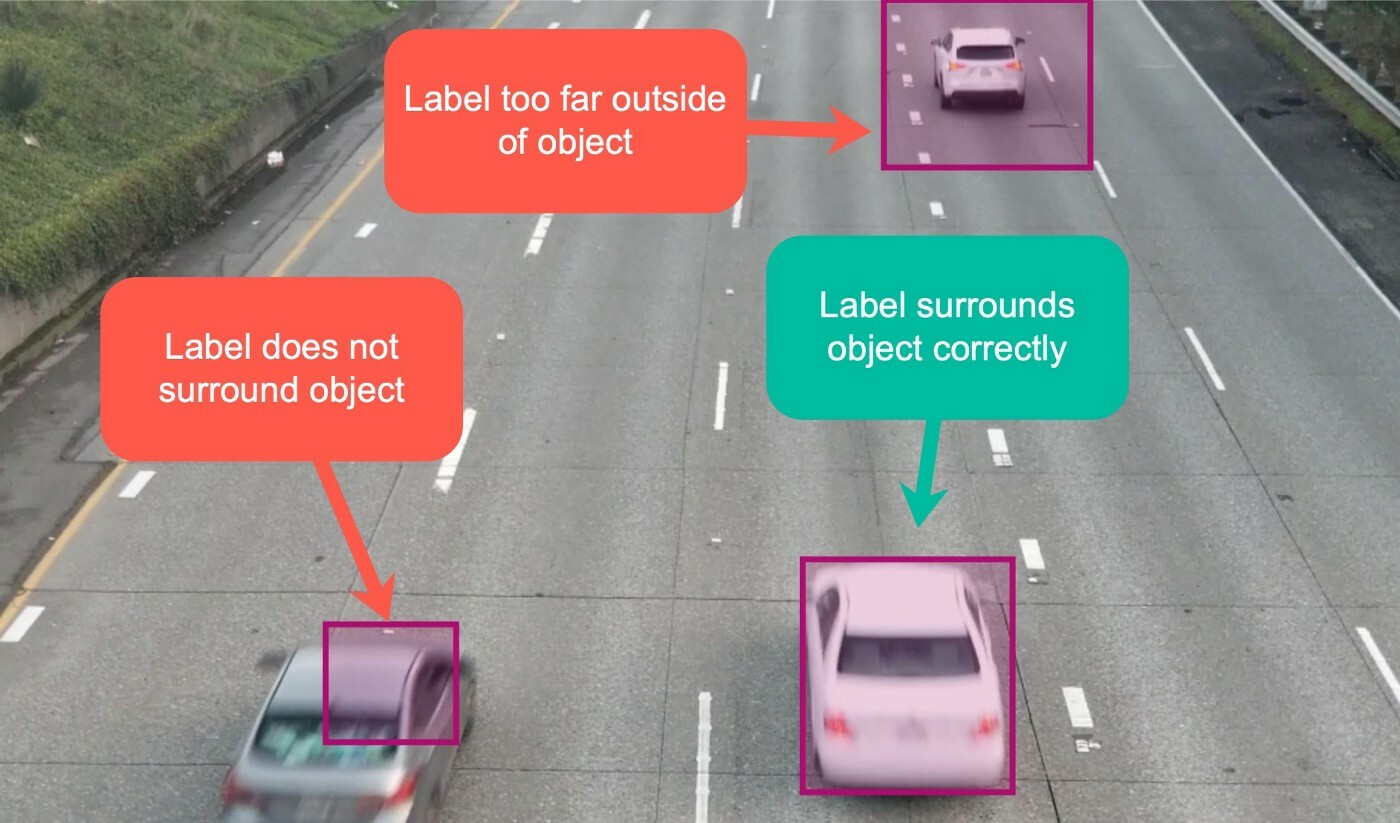
Таким образом разработчики и компания теряют очень много времени и ресурсов. Но это еще не самое страшное. Ведь им придется выбирать: трать снова деньги и время на исправление ошибок в разметке и переобучение модели или полностью закрывать проект из-за недостатка ресурсов.
«Если 80% нашей работы — это подготовка данных, почему мы не думаем, что обеспечение качества данных — самое важное для команды, занимающейся машинным обучением?» - Основатель deeplearning.ai и бывший руководитель Google Brain Эндрю Ын.
На конференции “Искусственный интеллект 2022” наш Генеральный директор Георгий Каспарьянц смог еще лаконичнее выразить эту мысль:
Качество данных - это верхняя оценка качества технологии.
Получается еще на этапе нахождения датасета мы можем испортить всю технологию.
Именно поэтому мы в компании LabelMe уделяем каждому изображению и каждому слову в тексте, проводим дополнительный этап валидации, обучаем и разметчиков и проверяющих. Наша задача - предусмотреть все нюансы, чтобы заказчик получит датасет, с которым обучение модели будет быстрым, а результаты точными.
Вы можете ознакомиться с примерами нашей разметки в разделе "Каталог датасетов".