
— Синтез речи для коммуникации с пользователями
— Компьютерное зрение в строительной индустрии
— ИИ в страховании
— AI в здравоохранении Москвы
Одним из спикеров стал основатель и генеральный директор компании LabelMe - Георгий Каспарьянц. В своём докладе он осветил проблему качества данных. Ведь данные - это фундамент, на котором обучается любая нейросетевая модель.
"Качество данных - это верхняя оценка качества технологии. В дело вступает принцип Джорджа Фьючела: «Мусор на входе – мусор на выходе».
Получается еще на этапе нахождения датасета мы можем испортить всю технологию." - отмечает Георгий Каспарьянц.
Генеральный директор LabelMe выделяет три основных фактора влияющих на качество данных, о которых мы расскажем ниже.
1. "Сырость данных"

“Сырость данных” — когда данные не приведены к единому виду. Например, присутствуют битые картинки или видео, разные разрешения и форматы или json-файлы содержат ошибки. Это очень распространенная проблемы, но, к счастью, она не влияет на точность модели. Только прибавляет работы вашим дата сайентистам.
“Сырость данных” чаще всего возникает из-за децентрализованной системы выполнения. Например, данные собирались или размечались с помощью аутсорсинга, где каждый исполнитель отступает от ТЗ и это никак не контролируется. Также разметчики могут использовать разный софт, из-за чего отличаются форматы выходных данных. И, конечно же, отсутствие тщательной проверки.
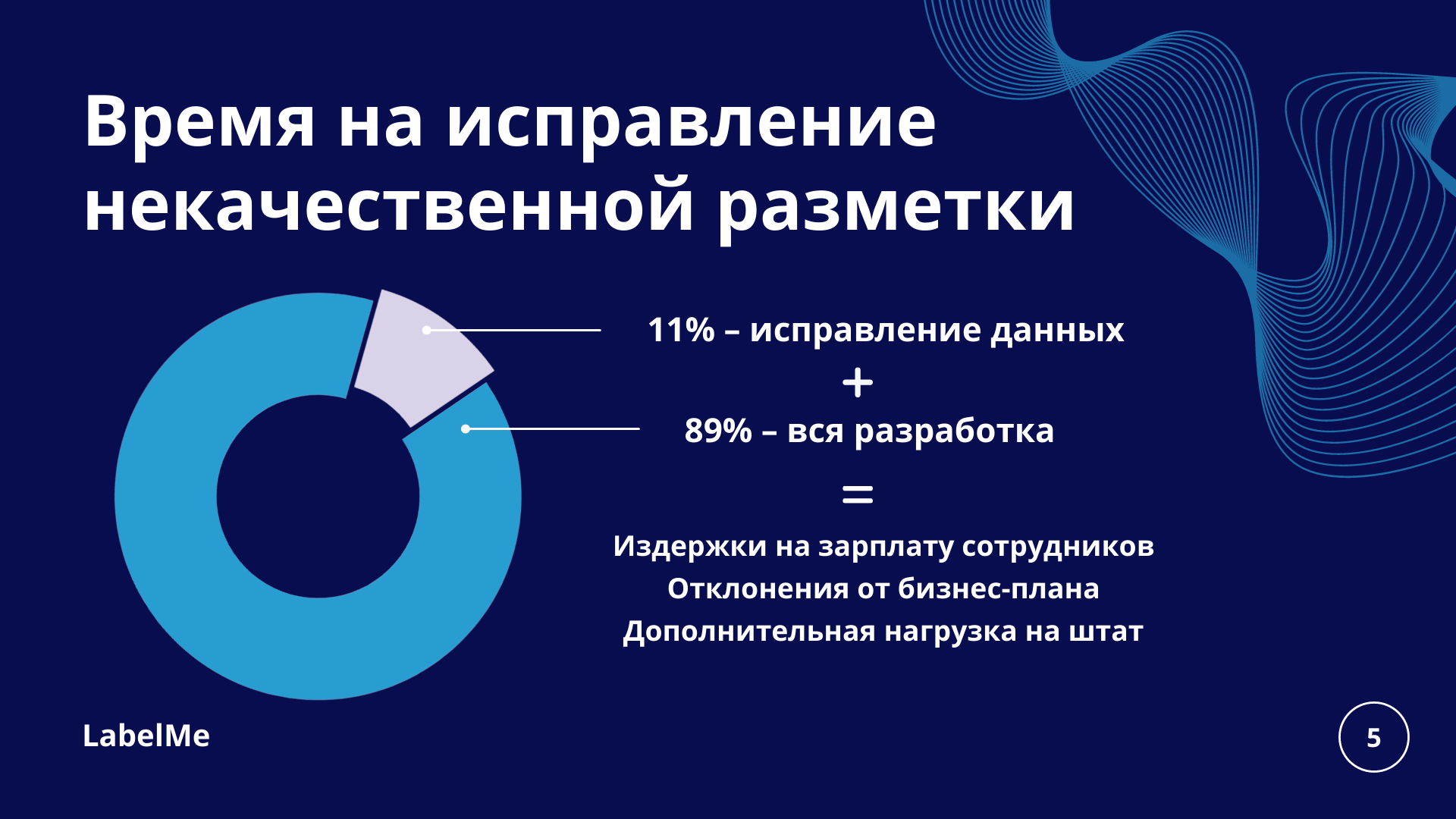
Чтобы избежать “сырости” в данных, необходимо стандартизировать этап проверки данных. Например, в LabelMe данные проходят обязательный этап проверки, на котором отсеиваются проблемные файлы и отправляются на доработку. Помимо разметчиков мы выделяем команду проверяющих, которые занимаются исключительно валидацией.
2. Некачественная разметка

Некачественная разметка — когда размечены не все классы или они размечены с логическими ошибками, извлечены не все сущности, неточные границы в
сегментации и так далее. Если не предпринять меры по исправлению, на выходе можно получить неточную модель.
Проблемы с качеством разметки чаще всего возникают, когда ее выполняют люди без опыта. Они могут не знать все нюансы. Например, как разметить объект, который перекрывает другой объект.
Также важна точностью ТЗ: если оно прописано не детально, то исполнитель может допустить ошибку, даже не подозревая об этом. В масштабах объемного датасета - это может стать критическим недочетом.
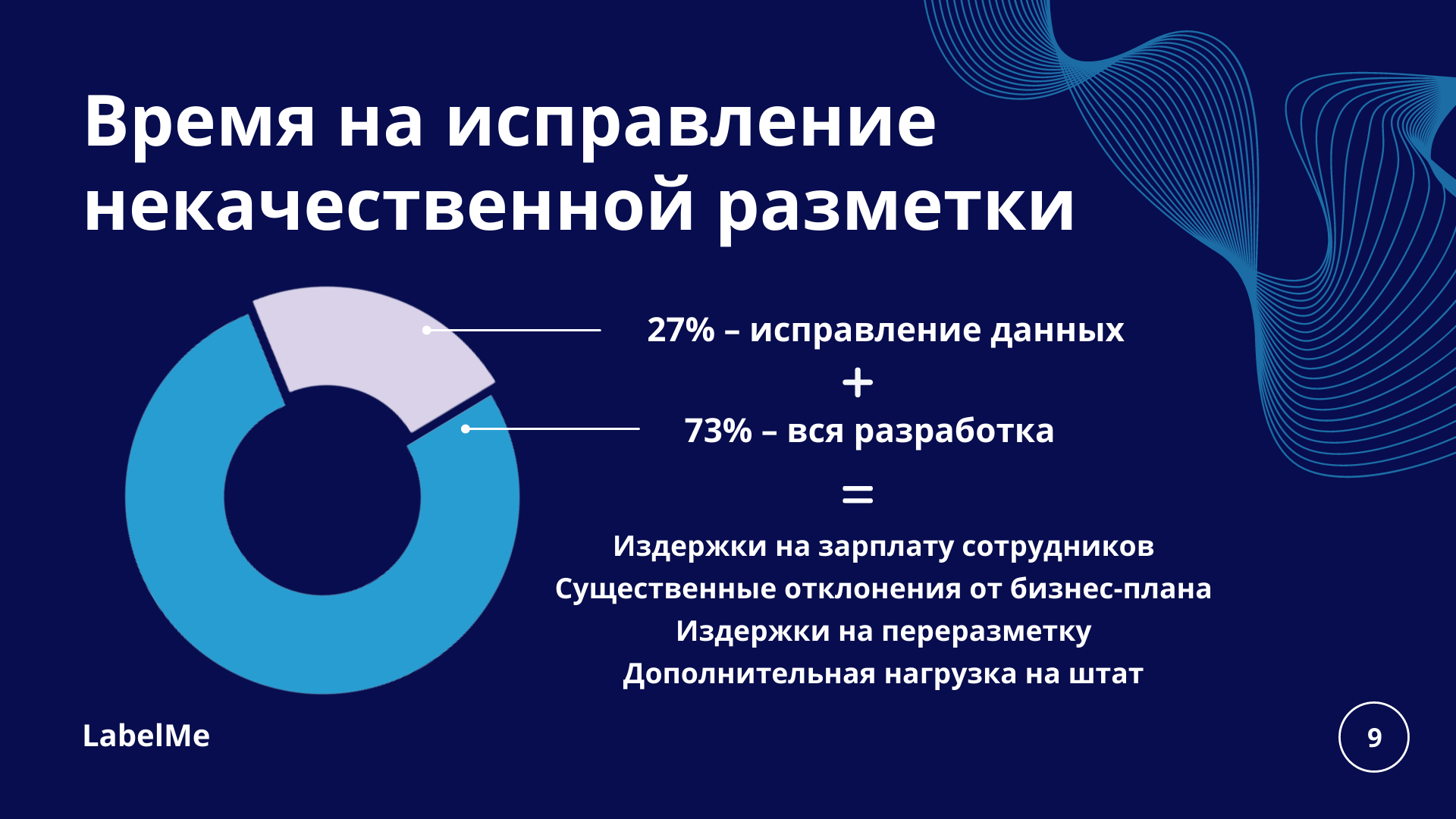
Что касается самой разметки — необходимо допускать к работе только разметчиков с опытом и в мельчайших деталях прорабатывать ТЗ. Нужно постараться предвидеть проблемы, которые могут возникнуть в ходе аннотации и дать исполнителям решение или подробную инструкцию.
Говоря о личном опыте, мы в LabelMe формируем отделы по специализациям. Разметчик, который хорош в CV - занимает CV. Таким образом мы используем сильные стороны наших специалистов для решения конкретных задач.
2. Полнота датасета

Полнота датасета — когда набор данных содержит не все инвариантные преобразования объектов. Например, для задач детекции поз нет данных о людях с поднятыми руками. Из-за этого нейросеть по итогу может попросту не работать с некоторыми из основных задач.
Неполнота данных чаще всего возникает тогда, когда на стадии формирования ТЗ не учитываются различные кейсы используемой технологии. В зависимости от задачи, которую должен решать алгоритм, могла быть допущена логическая ошибка, не учитывающая инвариативные преобразование: ракурсы, позы, освещение и так далее.

С полнотой данных — самая большая проблема. Если проблемы обнаружена несвоевременно, компании приходится дособирать и доразмечать данные. Это фактически замораживает весь процесс и открывает разработку ML-продукта на самый первый этап. Начиная всё с нуля, важно внимательно изучить все смежные кейсы, дополнить тз и оперативно приступить к доработкам датасета.
Если и на второй раз возникнут логические проблемы при составлении ТЗ, то придется вновь повторять всю процедуру. Чтобы защитить наших клиентов от этого, специалисты LabelMe углубляются в каждый заказ и предлагают внести правки в логику ТЗ. Таким образом мы экономим средства и время наших клиентов.
Именно поэтому важно предусмотреть все три фактора и выбрать опытного подрядчика для работы над вашими данными. Хотим напомнить, что LabelMe предоставляет бесплатный тестовый датасет по ТЗ заказчика. Это позволяет подробно изучить специфику заказа, рассчитать справедливую стоимость и доработать инструкции, чтобы добиться наилучшего качества датасета.