
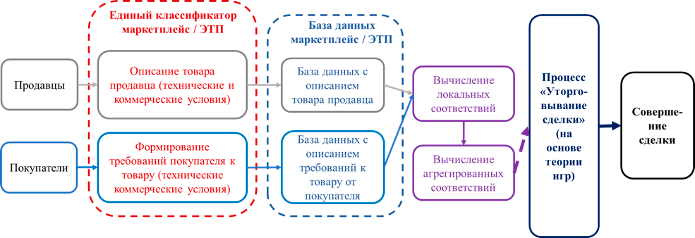
В рамках поведенческого анализа аудитории специалисты компании заказчика обнаружили, что часто пользователи размещают товары, составляя к ним неверные описания. В связи с этим покупателям сложнее искать необходимые позиции на сайте. Цель заказчика - на этапе создания объявления не давать продавцам писать неверные описания.
Создание нейросети, умеющей матчить товары и описание - это отдельная трудоемкая задача Deep Learning, для которой нужны данные, совмещающие в себе парсинг описаний товаров и парсинг их изображений. Сейчас мы подробно расскажем, как мы решили проблему заказчика, подготовив уникальный и объемный набор обучающих данных.
Задача заказчика
По изображениям товаров проставить для каждого релевантный метатег.
Всего было выделено более 10,000 различных метатегов, предоставленных заказчиком. Далее по метатегам на изображениях и описании товаров с помощью языковой модели заказчик планировал делать выводы о соответствии товара и описания.
Решение
Опираясь на полученную информацию, первоначальное ТЗ и переговоры с ML-специалистами компании заказчика, команда LabelMe подготовила бесплатный тестовый датасет. В ходе его подготовки проводился замер для определения справедливой стоимости выполнения заказа за единицу времени.
Так как общий пайплайн выполнения проекта мы закладываем на стадии тестового датасета, наша команда предусмотрела еще один неочевидный фактор. Чтобы разметчик смог корректно классифицировать изображения, важно понимать особенности каждого вида товаров.
Также в ходе работы над тестовым были выдвинуты гипотезы по правкам в первоначальное техническое задание с целью решения возможных проблем на этапе обучения модели. Руководитель отдела разметки заметил, что в качестве примеров заказчик предоставил только постановочные фотографии товаров, сделанные производителем. Это делало данные практически синтетическими, так как они могли значительно отличаться от реальных снимков, сделанных пользователями-продавцами.

Поэтому, после предоставления тестового датасета, наши специалисты предложили расширить набор данных пользовательскими снимками товаров. Для увеличения точности обучающего датасета было также предложено выйти за пределы общего рубрикатора на сайте и добавить более корректные теги. Например, модели устройств, бренды одежды, названия производителей и так далее.
Выполнение проекта
Шаг 1: поиск разметчиков по специализациям
Чтобы разметчики не ошибались в процессе классификации и выставления метатегов, мы проводили тщательный отбор. Первым делом был составлен список основных категорий товаров:
— Транспорт
— Недвижимость
— Личные вещи
— Для дома и дачи
— Электроника
— Хобби и отдых
— Животные
Далее мы провели опрос среди разметчиков, в котором уточняли, в каких категориях они разбираются лучше. После этого каждый из них прошел обучение и инструктаж по выстроенному пайплайну, завершающийся тестовы заданием. Необходимо было удостовериться в двух вещах:
1. Разметчик действительно понял, как именно нужно размечать
2. Он хорошо разбирается в товарах, указанной им категории
Шаг 2: сбор дополнительных данных
Озвученная нашими специалистами гипотеза о “синтетичности” исходных изображений была положительно воспринята заказчиком. Было решено изменить ТЗ и дополнить задачу сбором дополнительных данных.
Изначальный набор предоставленных заказчиком изображений был скорректирован: 50% - фотографии, сделанные производителем, и 50% - пользовательские фото товаров их архивных объявлений.
Также заказчик захотел расширить обучающий датасет примерами “реальных фотографий” на 50% от общего объема и заказал услугу по сбору данных.
Мы предложили два варианты реализации сбора:
1. Парсинг изображений из открытых источников
2. Привлечение исполнителей для съемки разных объектов по релевантным классам
После были проведены тесты по замерам стоимости и сроков для обоих вариантов, по итогам которых был выбран первый. Ключевым фактором стала более низкая стоимость выполнения.
Шаг 3: процесс классификации
С целью повышения точности обучающего датасета мы использовали метод мультиклассовой разметки: по классам и подклассам. Например, в категории Электроника были подклассы:
– Ноутбуки
– Компьютеры
– Смартфоны
– Планшеты
– Игровые приставки
– Умные колонки
– Умные часы
– Телевизоры
– Наушники
– Электронные книги
– и др.
Выстроенный пайплайн включал в себя три итерации обработки данных:
1. Определение категории товара
2. Определение подкласса категории
3. Присвоение метатегов
Весь рабочий процесс разметки проходил в нашем собственном ПО — TinderLabel. Благодаря переработанному принципу взаимодействия с данными, его использование позволило многократно ускорить процессы выполнения задачи.
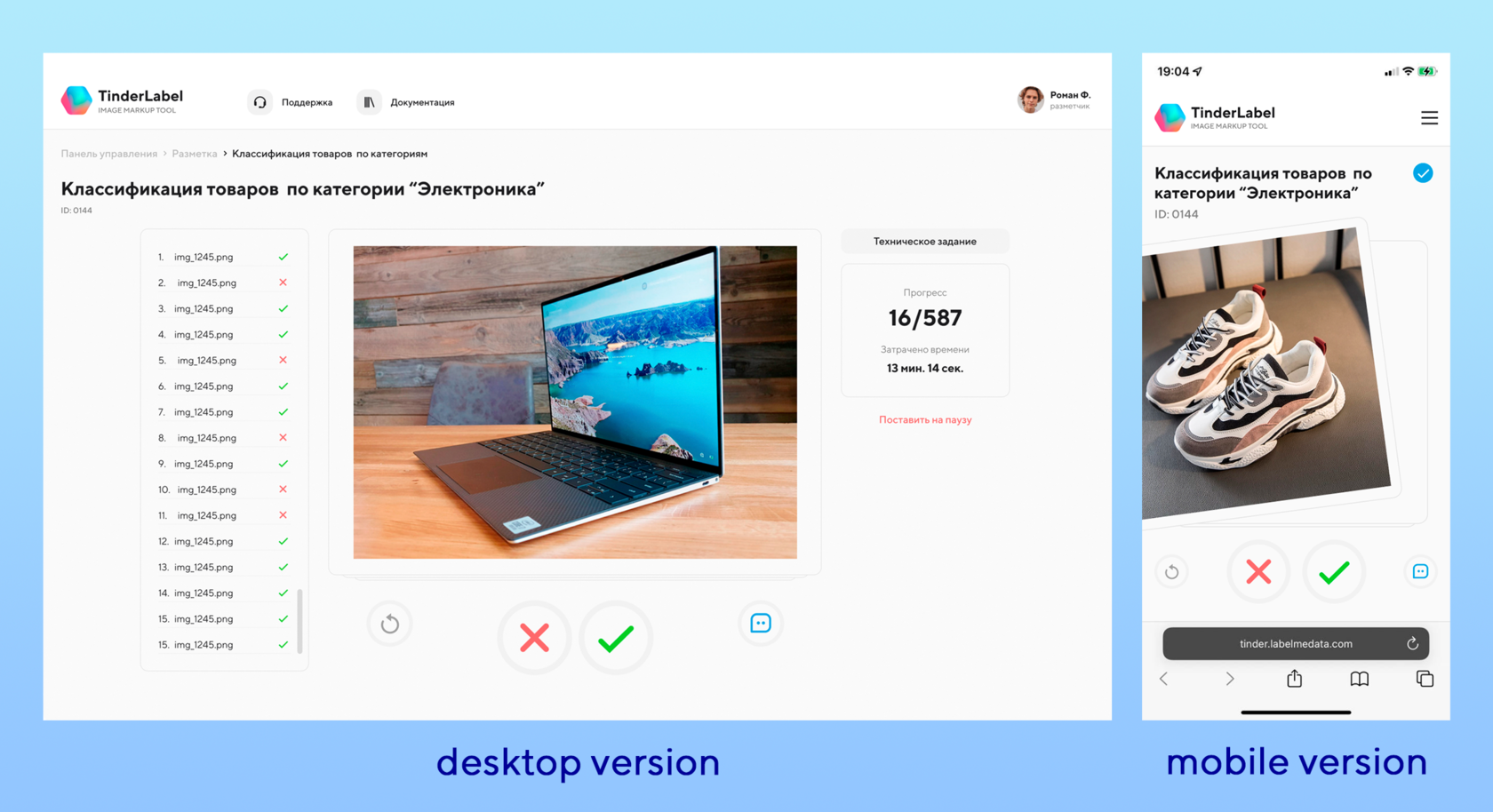
Разметчик, указавший в опросе специализацию по электронике, должен был свайпать вправо только те изображения, которые релевантны его категории. Или нажимать аналогичные кнопки в веб версии.
Все изображения были загружены на единый сервер, после чего партиями выгружались для каждого исполнителя. После того, как он свайпал изображения нужного класса, они уже не показывались другим разметчикам тех же категорий. Также и с изображениями других категорий: после свайпа влево, они не показывались никому из разметчиков “электроники”.
Благодаря встроенной в ПО аналитике, кураторы проекта могли оценивать скорость и объем классификации по каждой категории. Если они видели просадки или недостаток разметчиков по какой-либо категории – привлекались новые сотрудники.
Далее рассортированные по категориям изображения отправлялись на второй этап: разметку по подклассам. В отличие от первой итерации, здесь не используется метод свайпа. Вместо этого рядом с изображением появляются кнопки соответствующих подклассов. После клика – изображение автоматически сменяется следующим.
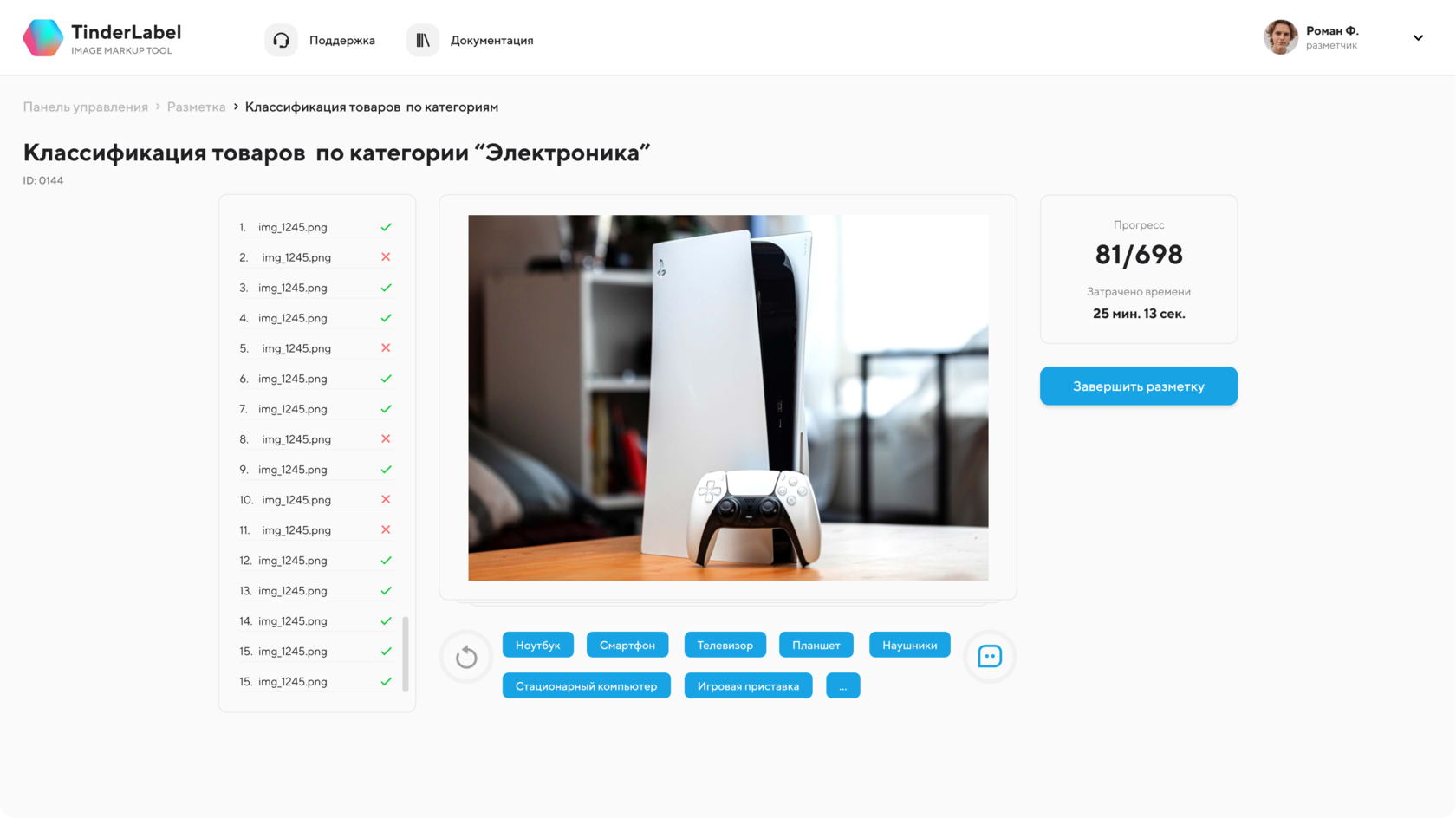
Ключевой особенностью этого этапа является интеграция встроенной в ПО нейросети. Она обучается в ходе выполнения. После того, как разметчики "отсортируют" по 100-150 изображений каждого класса, нейросеть начнет прогнозировать верный вариант. Таким образом, ближе к середине выполнения этапа разметчик превращается в проверяющего. Предполагаемый подкласс изображения начинается подсвечиваться.
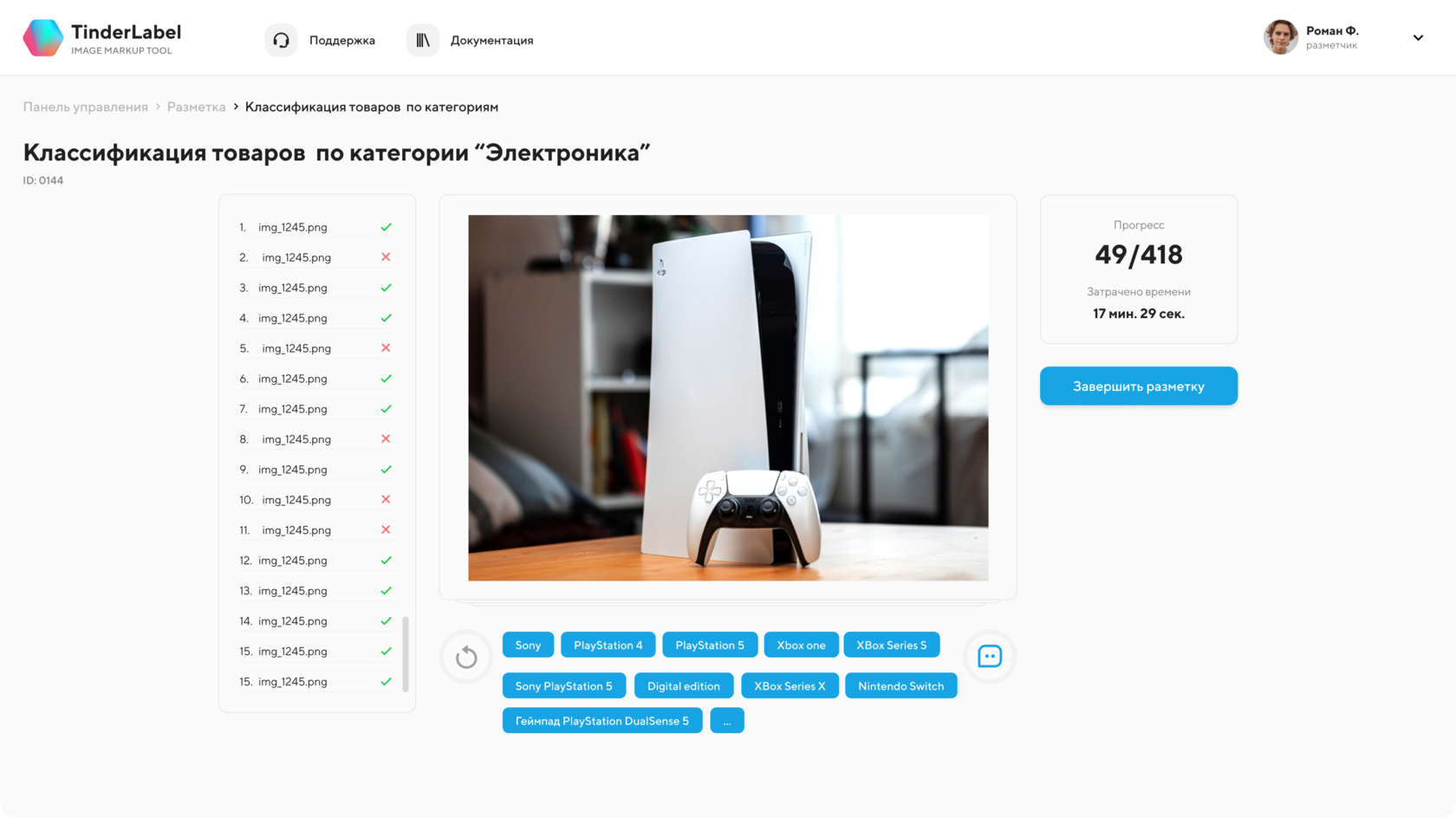
На третьей итерации разметчику остается только дописать актуальный тег. Если же он не может прописать тег конкретного изображения, он может пропустить его. Тогда оно автоматически вернется в работу и попадает другому разметчику этой же специализации.
Результат
На выполнение всех этапов работы, включающих дополнительный сбор и три этапа классификации, у нас ушло 3 недели. Конечным результатом стал архив с изображениями, рассортированный согласно установленной логике, и файл с метаданными, необходимыми для обучения.
Мы проводили итеративное согласование после завершения каждой подзадачи. Это позволяло исправлять неточности на ранних этапах и оперативно мониторить качество работы.
Весь объем работ был сдан раньше намеченного дедлайна благодаря четкой проработке пайплайна, привлечению большего числа разметчиков по всем направлениям специализации и работе в собственном ПО. Предобученую в процессе работы нейросеть мы также передали заказчику для дальнейшего изучения и улучшения.
Заказчик остался доволен качеством и сроками. Сейчас идет обучение модели на наших данных, поэтому рано говорить продакшене и общем доступе, но мы с нетерпением ждем возможности прикоснуться к внедренному решению.