
Однако, для новичков интерфейс и управление может показаться непонятным. Мы решили исправить это и разобрать разметку в CVAT на примере задач семантической сегментации.
Шаг 1: регистрация и создание проекта в CVAT
Как только мы попадаем на сайт, нам сразу предлагают авторизоваться в личном кабинете. Без этого этапа вы не сможете ни присоединиться к выполнению, если вы исполнитель, ни создать свой собственный проект.
Если аккаунта нет, пройдите простую процедуру регистрации.
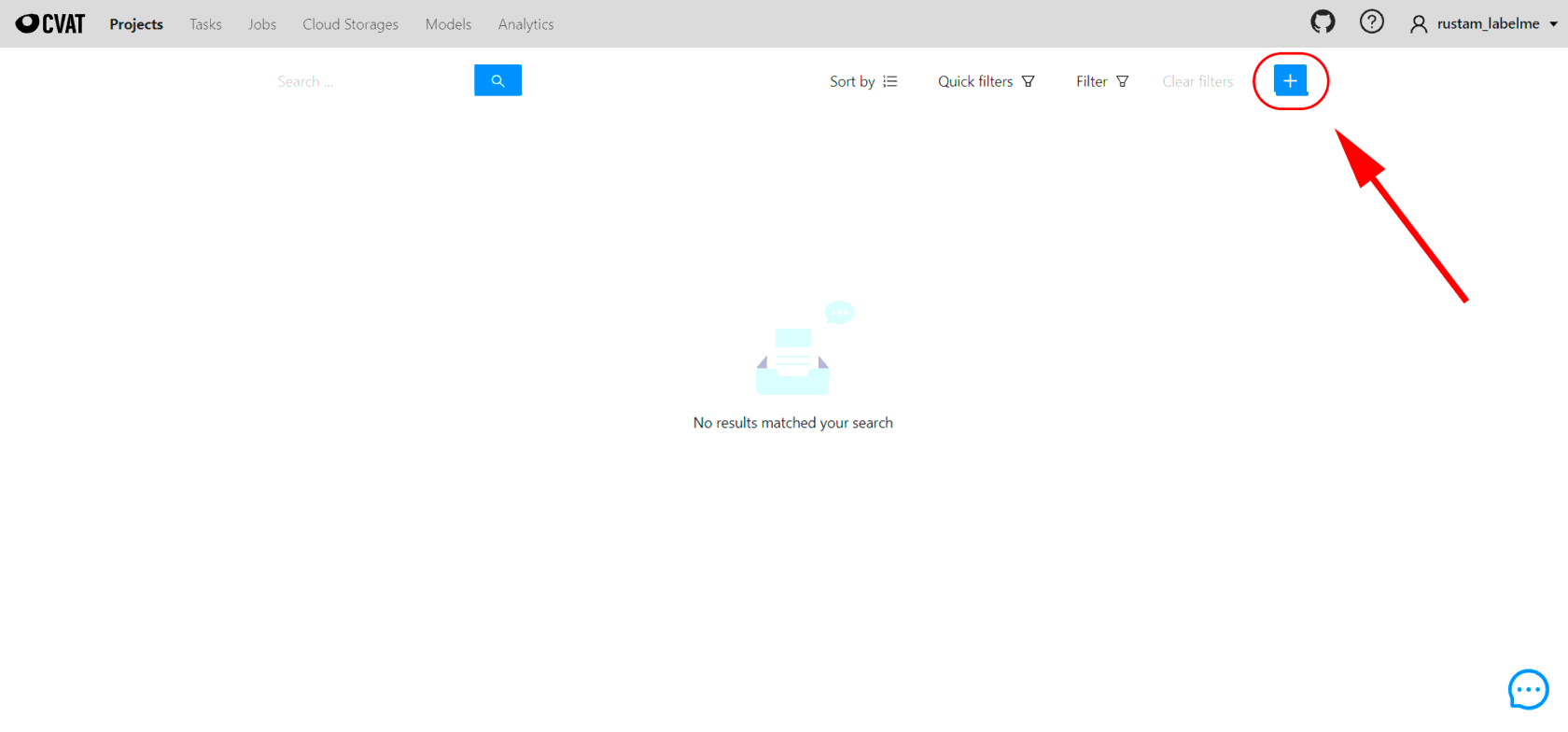
Далее вы попадаете в основной интерфейс CVAT. Чтобы создать свой первый проект, переходим во вкладку Project и кликаем на + (см. скриншот ниже)
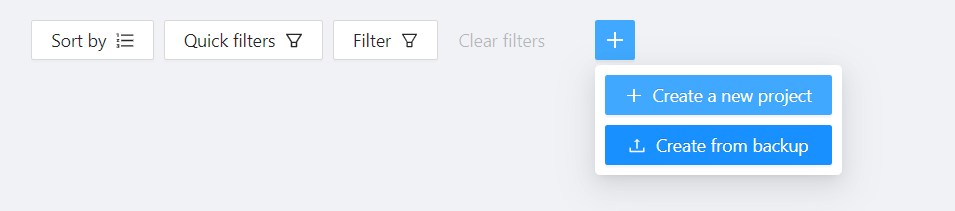
Выбираем “Create a new project” и начинаем заполнять информацию.
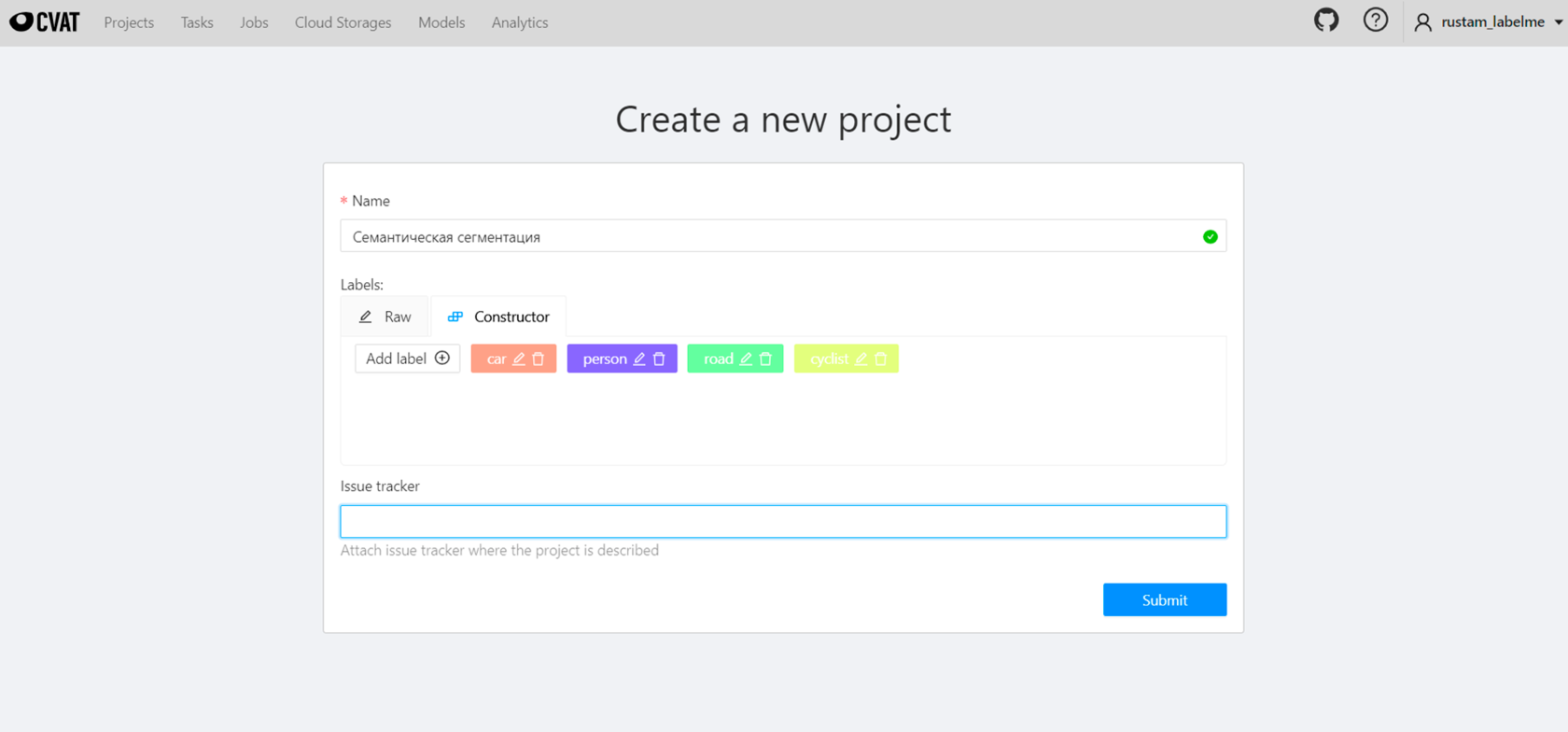
На скриншоте мы уже ввели название проекта “Семантическая сегментация” и указали классы и их цвета, актуальные для наших изображений. А именно
background:0,0,0::
car:255,96,55::
person:44,0,255::
road:102,255,102::
cyclist:221,255,51::
Далее, нам нужно создать Task. Для этого заходим в Project, выбираем созданный нами проект и в открывшемся окне кликаем на + (см. скриншот ниже).
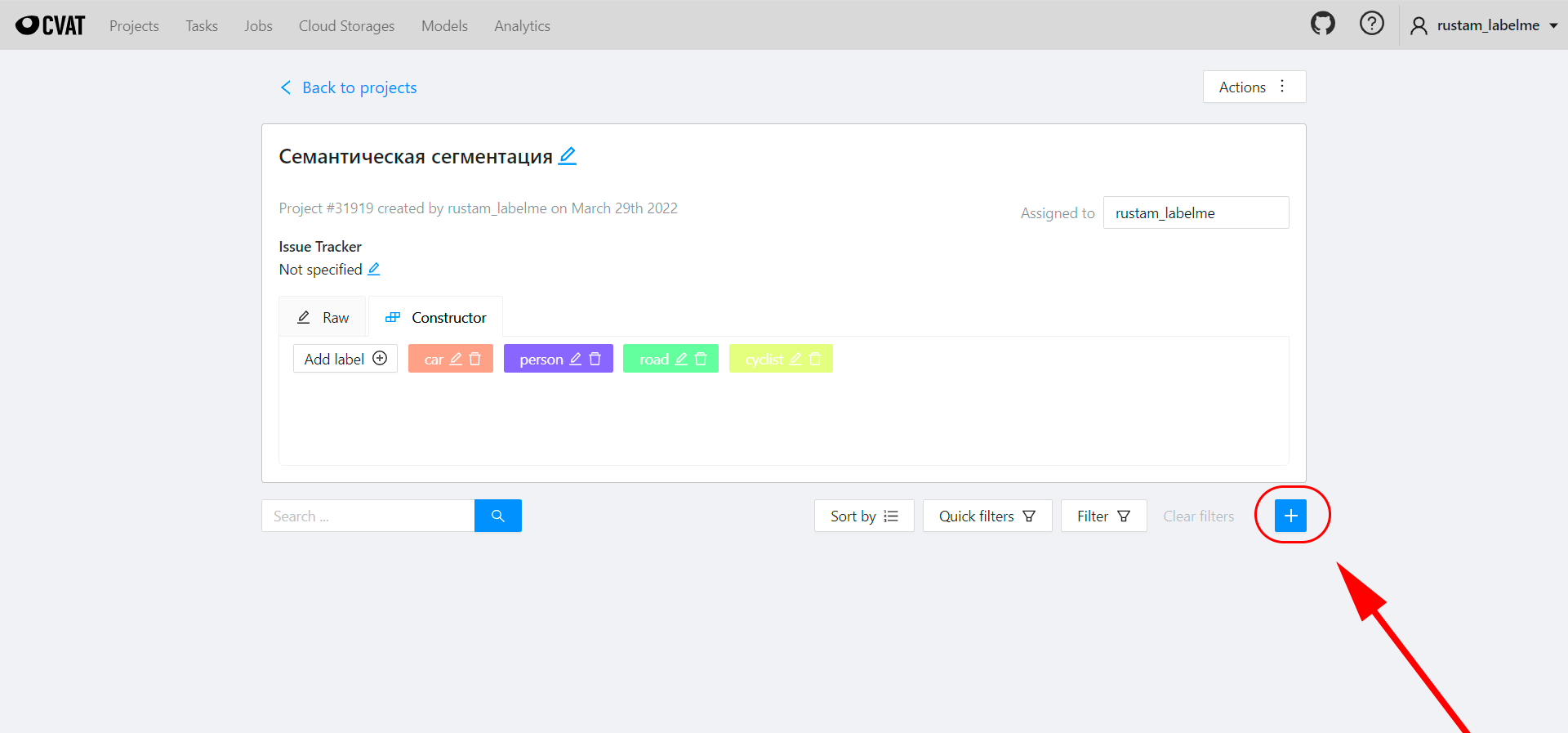
В новом окне нам нужно написать имя таска и загрузить исходные данные. Можно либо перетащить изображения по одному или загрузить сразу архив.
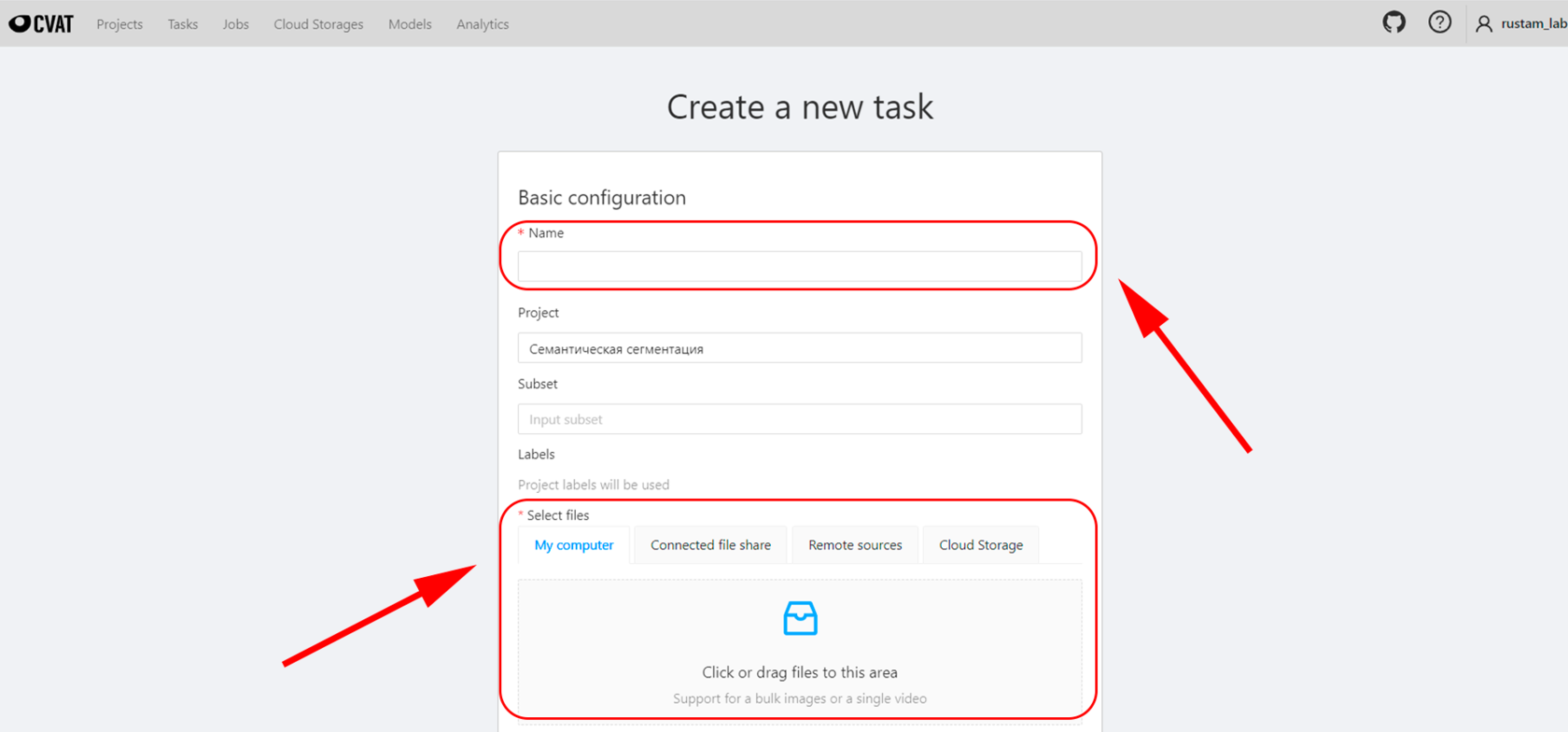
Также нужно задать дополнительные настройки ниже в разделе Advanced configuration. Кликните по нему, чтобы открылось окно. В нем нас будут интересовать 3 параметра:
1. Image quality - по умолчанию CVAT сжимает качество до 70%. Поэтому мы рекомендуем выставлять 100%, чтобы работать с исходным качеством изображений.
2. Segment size - этот параметр отвечает за то, по отдельных джобов будет по этому проекту. Например, если у вас 100 изображений и вы напишите 1, то в одном джобе будут все 100 изображений. Если у вас есть 10 человек, то можете вписать 10 и тогда таск будет разбит на 10 джобов. Каждый по 10 изображений, на которые вы сможете дать доступ к разметке. Учитывайте этот параметр при командной работе.
3. Choose format - конкретно для сегментации мы рекомендуем использовать segmentation mask (выбирается в выпадающем списке).
Не забудьте нажать на кнопку submit в конце страницы, чтобы сохранить свои настройки.
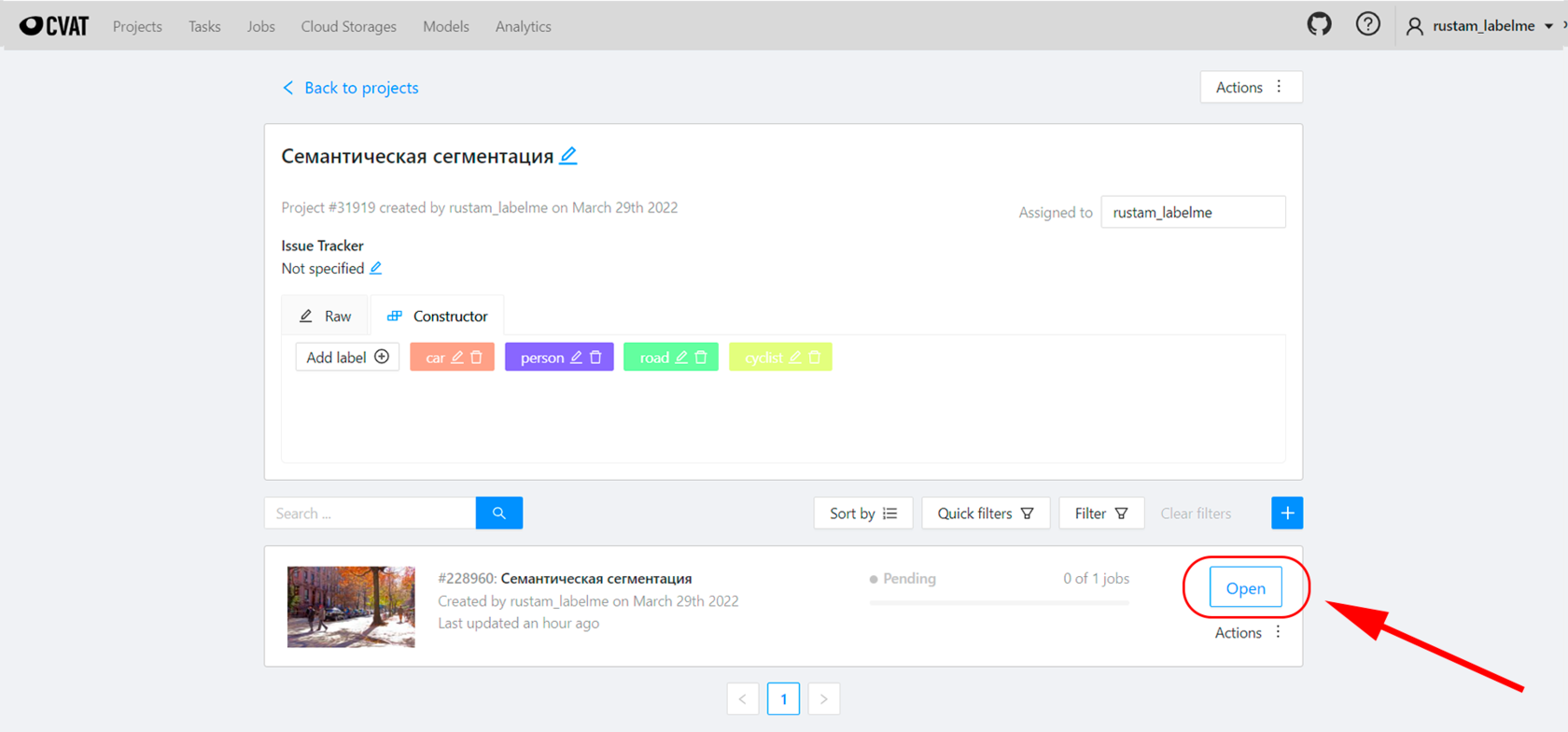
После всех этих манипуляций в окне вашего таска появится первый джоб. Кликните по кнопке Open и всё, можно будет приступить к разметке (см. скриншот ниже).
Шаг 2: Семантическая сегментация объектов в CVAT
ВНИМАНИЕ: все описанные действия относятся к многоклассовой семантической сегментации. Ее используют для задач, в которых на одной сцене могут присутствовать сразу несколько классов объектов. В нашем случае это машины, люди, дорога, велосипедисты. Но бывает и так, что нужно сегментировать только один объект в кадре. Например, кружку. В таком случае вы просто создаете один класс.
Итак, мы попадем в основной интерфейс для разметки в CVAT. Перед нами представлено само изображение, справа меню с объектами, слоями и классами, а слева инструменты.
Для сегментации изображений нам нужен инструмент polygon (полигоны).
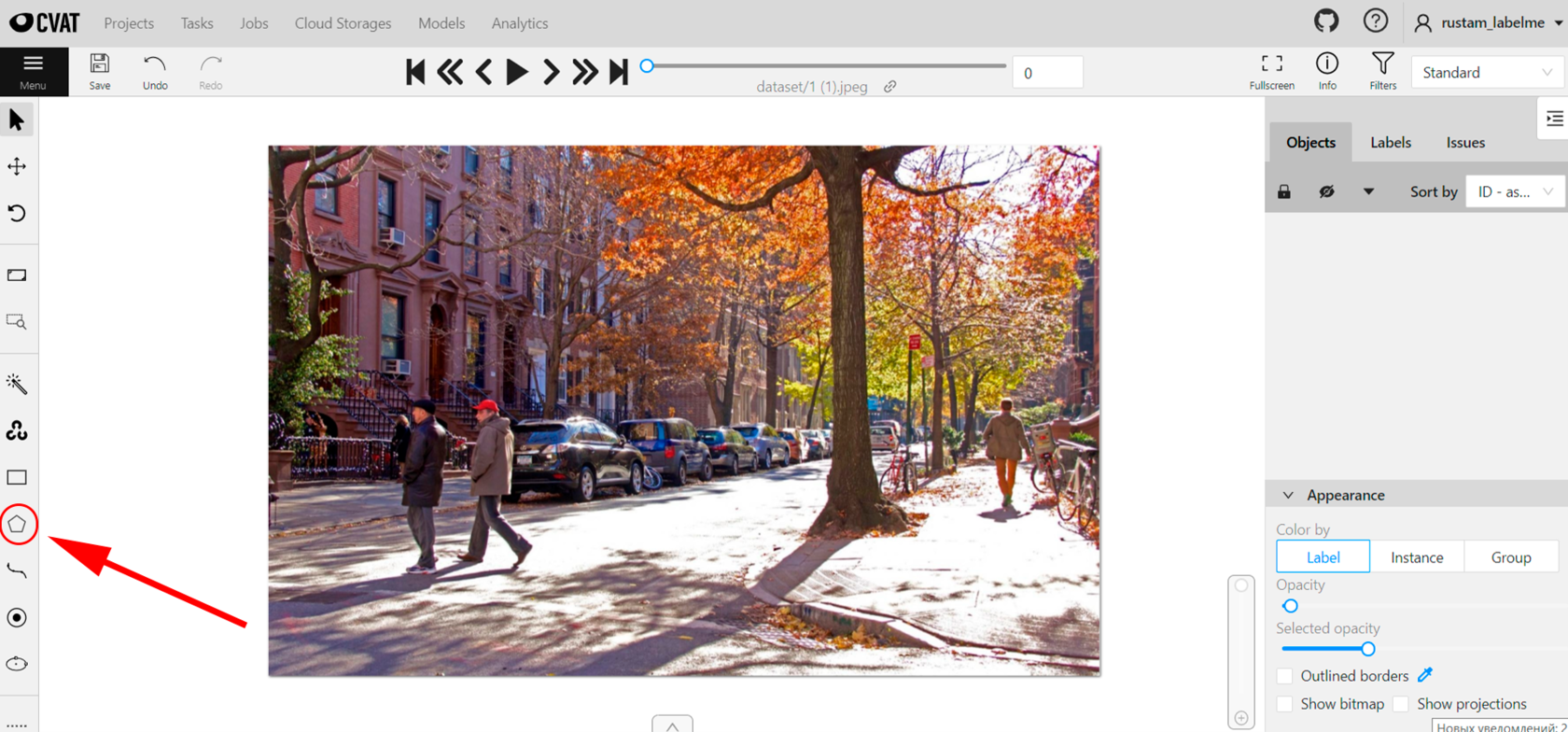
При наведении на него, откроется окно с выбором классов. Выберите тот, с которого хотите начать и нажмите Shape.
Теперь наша задача — как можно аккуратнее обвести нужный объект по контуру. Сделать это одним движением - очень сложно, поэтому мы используем полигоны, расставляя точки, которые потом будут соединены в одну маску. Вот как выглядит полностью разметка одного объекта:
Учитывайте то, что эта видео ускорено в несколько раз. На самом деле процесс сегментации достаточно долгий, так как важно очень точно соблюсти контуры.
Точки можно расставлять двумя способами:
1. Вести курсор и вручную ставить точки, нажимая на левую кнопку мыши. Пример ниже:
2. Зажимайте Shift и просто ведите курсом по контуру объекта. Точку будут ставиться автоматически с одинаковыми небольшими интервалами. Этот способ подойдет тем, кто хорошо чувствует и контролирует движение курсора. Комбинация работает как с мышью, так и с тачпадом ноутбуков. Пример ниже:
Следующая неочевидная вещь, полезная при сегментации изображений — отмена неправильно поставленных точек. Рефлекторно многие разметчики нажимают комбинацию Ctrl+Z, однако это неправильно. Это комбинация отменяет маску целиком, а не точку.
Чтобы отменять неправильные точки, нужно кликать на правую кнопку мыши. Пример ниже:
Когда вы проставите точки по всему контуру объекта, маску необходимо закрыть. Для этого доведите последнюю точку до первой и нажмите английскую клавишу N. После этого появится завершенная маска с цветом, соответствующим выбранному классу. Пример ниже:
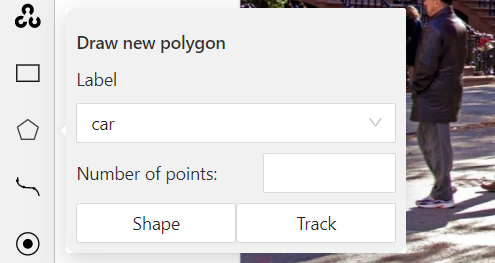
Следующий лайфхак, которым мы хотим поделиться связан с разметкой границ между двумя соприкасающимися объектами. Например, на нашем фото контур человека и машины пересекаются. В этом месте уже стоят точки от маски пешехода.
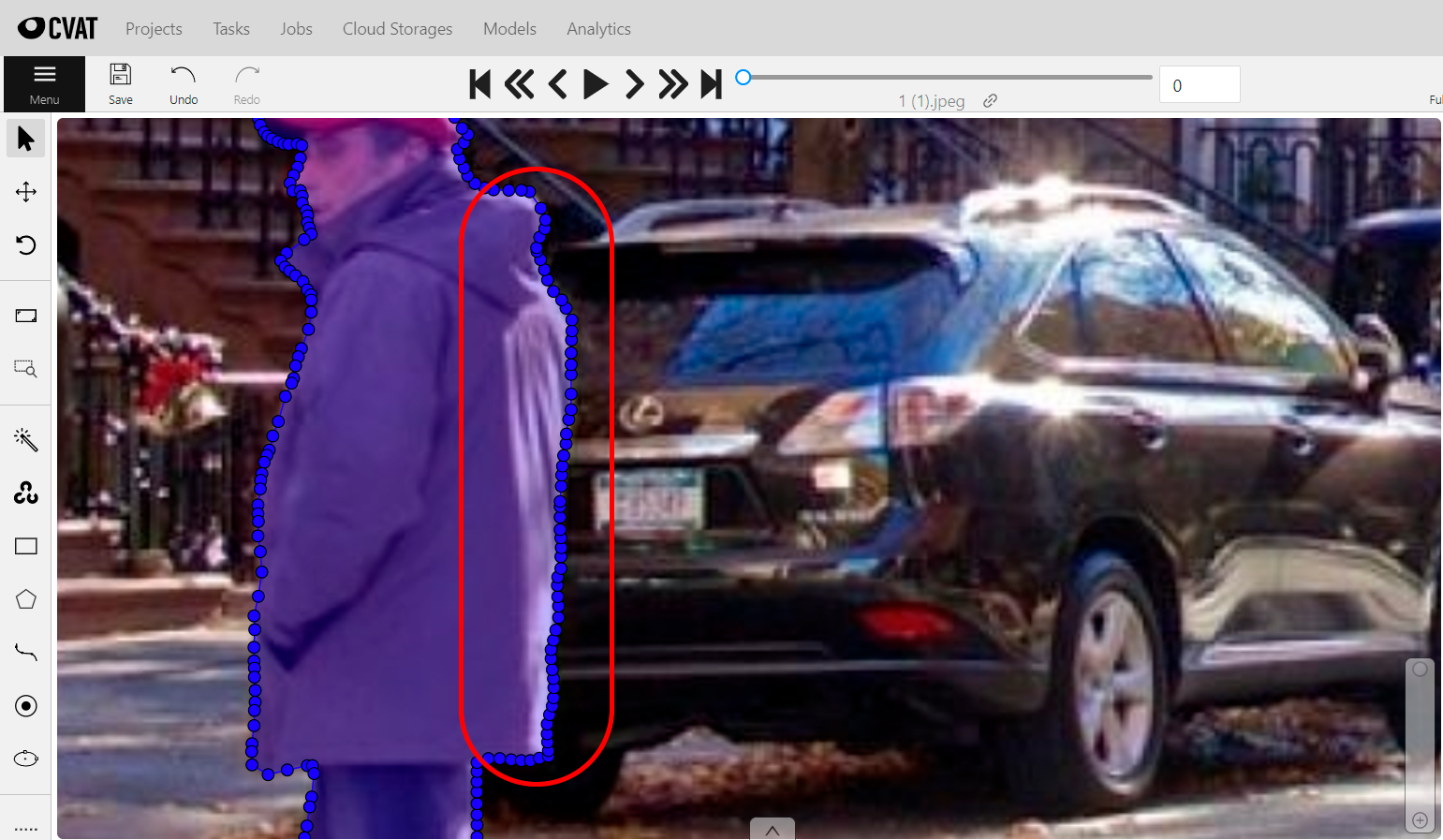
Как быть в такой ситуации? Чтобы не размечать по одному и тому же контуру и сделать всё аккуратно, достаточно воспользоваться еще одной фишкой CVAT. В тех местах, где контур масок соприкасается, нужно выбрать первую, вторую и последнюю точки соприкосновения. Сервис автоматически пометит остальные точки между ними. Пример ниже:
Таким образом мы сэкономили много времени, не размечая одно и то же два раза. Также можно и поступить с сегментацией дороги. Ведь она же соприкасается не только с машинами, но и с двумя пешеходами. Еще раз воспользуемся уже размеченные контуры и проблемные места получается аннотировать за считанные секунды. Ниже пример:
Таким образом можно разметить классы всех нужных объектов и перейти к экспорту уже размеченного датасета.
ВНИМАНИЕ: Напоминаем, что CVAT — это веб-инструмент. Ошибки с сервером или интернетом могут возникнуть в любой момент. Поэтому рекомендуем после сегментации каждого класс сохранять прогресс.

Шаг 3: Экспорт разметки
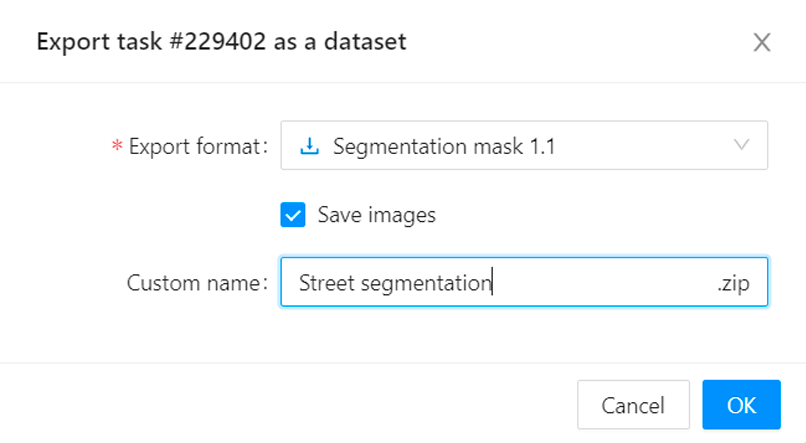
Чтобы экспортировать данные, кликаем на меню и выпавшем списке выбираем Export task dataset.
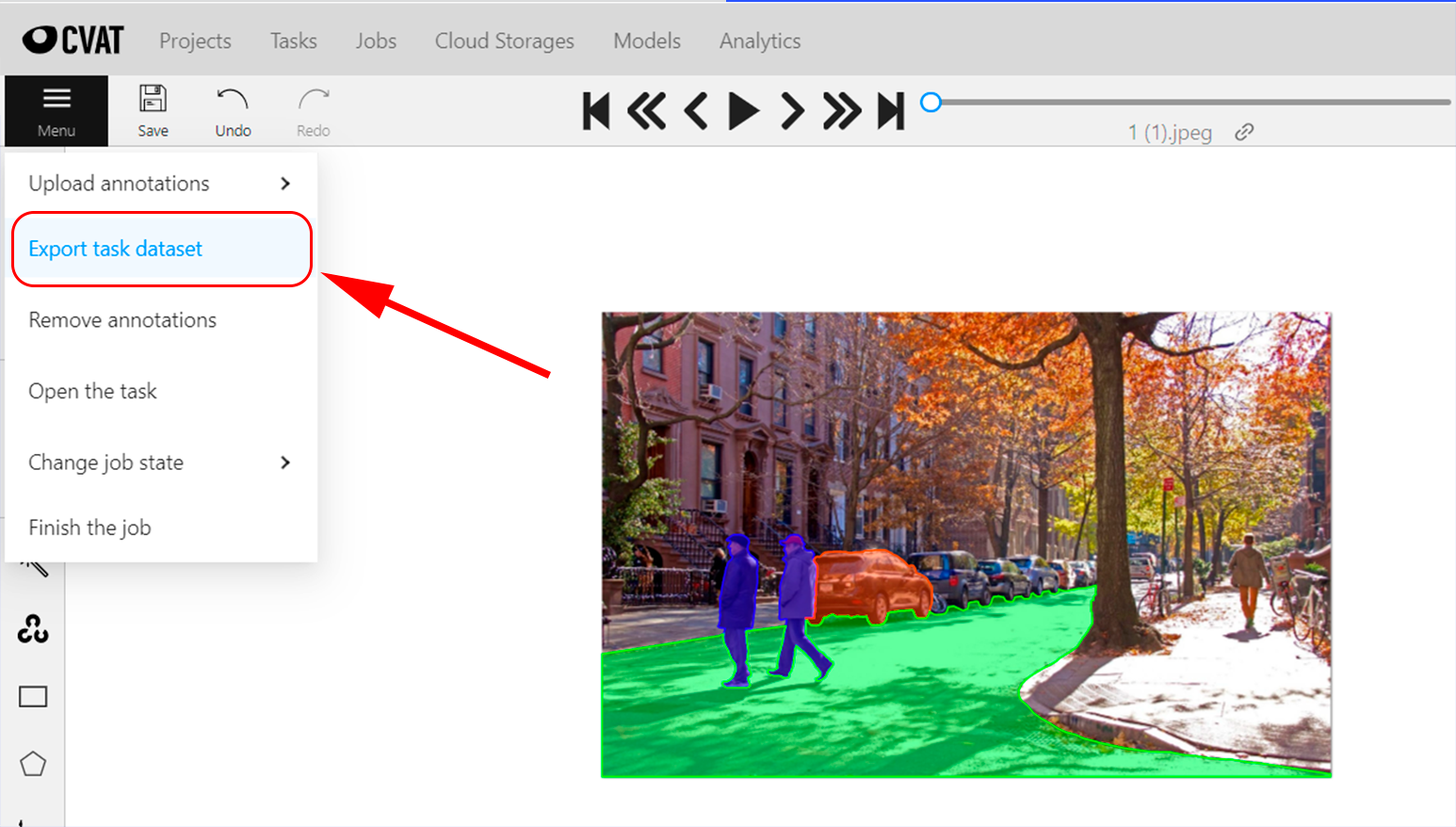
В появившемся окне нужно выбрать формат выгрузки (в случае сегментации изображений это segmentation mask), ставим галочку, чтобы в архиве были не только маски, но исходники, и даем название архиву.
1. Папку SegmentationObject - маски, где каждый объект помечен разными цветами
2. Папку SegmentationClass - маски по указанными вами классам
3. Папку JPEGImages - исходники размечаемых изображений
4. Папку ImageSets - с файлом метаданных исходников
5. labelmap.txt - цветовая карта классов
Заключение
В этой статье мы рассмотрели самые главные нюансы и способы семантической сегментации изображений в CVAT. Мы очень надеемся, что статья была вам полезна. Мы и впредь будет писать подобные материалы с разборами разных видов разметки и сервисов. Дайте нам знать, если у вас будут конкретные пожелания и вопросы.
Для обратной связи можете заполнить Google-форму: https://forms.gle/mx27xdoEudaaxnNX6